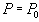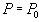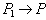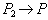и текстовые редакторы позволяют хранить
Таблица 1
| Цех | Иванов И.И. | Маша | ЛЕГО |
| Петя | Книги | Видео | |
| Саша | Компьютеры | ||
| Дима | Спорт | ||
| Петров П.П. | Артур | Ничем не интересуется | |
| Сидоров С.С. | Сергей | Компьютеры Книги | |
| Валерий | Книги | ||
| Станислав | Видео | ||
| Бухгалтерия | … | … |
Таблица 1 Таблица произвольной формыКонечно, и электронные таблицы, и текстовые редакторы позволяют хранить и обрабатывать данные очень гибко, но как быть, если требуется хранить информацию обо всех сотрудниках большого предприятия и периодически выдавать ответы на запросы типа "представить список всех сотрудников, принятых на работу не позднее трех лет назад, имеющих по крайней мере одного ребенка, не имеющих взысканий и с зарплатой не выше 1000 р.". Для получения ответов на подобные запросы и предназначены Системы Управления Базами Данных (СУБД). Классическая реляционная модель данных требует, чтобы данные хранились в так называемых плоских таблицах. Более точно, пользователи и приложения, обращающиеся к данным, должны работать с данными так, как если бы они размещались в таких таблицах. В упрощенном виде плоская таблица - это таблица, каждая ячейка которой может быть однозначно идентифицирована указанием строки и столбца таблицы. Кроме того, в одном столбце все ячейки должны содержать данные одного простого типа. Точное определение понятия "плоская таблица" дается в реляционной модели данных. Реляционная модель основана на теории множеств и математической логике. Такой фундамент обеспечивает математическую строгость реляционной модели данных. В свою очередь, на основе реляционной модели были разработаны различные языки для доступа к реляционным данным, такие как SEQUEL, SQL, QUEL и другие. Фактическим промышленным стандартом в настоящее время стал язык SQL (Structured Query Language - язык структурированных запросов). Различные фирмы, производители СУБД, предлагают свои реализации языка SQL. Эти реализации отличаются как друг от друга, так и от стандартизованного языка SQL. Это и хорошо и плохо. Хорошо это тем, что конкретная реализация языка, может включать в себя более широкие возможности по сравнению со стандартизованными SQL, например, больше типов данных, большее количество команд, больше дополнительных опций имеющихся команд. Такие возможности делают работу с конкретной СУБД более эффективной. Кроме того, такие нестандартные возможности языка проходят практическую апробацию и со временем могут быть включены в стандарт. Плохо же это тем, что различия в синтаксисе реализаций SQL затрудняют перенос приложений из одной системы в другую. Например, если приложение было написано для базы данных MS SQL Server с использованием своего диалекта SQL - языка Transact-SQL, то при переносе системы в базу данных ORACLE, не все конструкции языка будут понятны соответствующему диалекту SQL - языку PL/SQL. Взаимосвязь реляционной модели данных, стандарта языка SQL и различных его реализаций можно условно изобразить в виде следующей пирамиды:
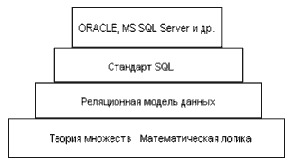 Каждый более высокий уровень основывается на понятиях, определенных на более низком уровне. На каждом из уровней используется своя терминология. Например, на уровне теории множеств мы говорим "множество", "подмножество декартового произведения", "кортеж". На уровне реляционной модели используем термины "домен", "отношение", "кортеж". На уровне стандарта SQL и конкретных реализаций используем термины "тип данных", "таблица", "строка таблицы". И каждый раз речь идет об одном и том же.Учебное пособие имеет следующую структуру.
Первая глава содержит небольшое введение в математическую теорию множеств, необходимое для введения фундаментального понятия "отношение".
Следующие три главы содержат описание собственно реляционной модели данных. Во второй главе вводятся базовые понятия реляционной модели данных, такие как "домен", "отношение", "атрибут", "кортеж", "ключ", "внешний ключ". В третьей главе вводится понятие целостности реляционных данных. Даются понятия целостности сущностей и целостности внешних ключей. В четвертой главе описывается язык доступа к реляционным данным - реляционная алгебра.
Пятая глава содержит краткое описание и примеры применения стандартного языка доступа к реляционным данным - языка SQL.
Шестая и седьмая главы посвящены важным вопросам правильного проектирования отношений. В этих главах вводятся нормальные формы отношений. Понятие нормальных форм необходимо для проектирования непротиворечивых и неизбыточных таблиц базы данных.
В восьмой главе описывается альтернативный способ разработки таблиц в нормальной форме - модель "сущность-связь".
Последние три главы посвящены важному для баз данных понятию "транзакция". Понятие транзакции является фундаментальным при рассмотрении таких вопросов как поддержание целостности базы данных, независимой одновременной работы большого количества пользователей, восстановления данных после сбоев системы.
Каждый более высокий уровень основывается на понятиях, определенных на более низком уровне. На каждом из уровней используется своя терминология. Например, на уровне теории множеств мы говорим "множество", "подмножество декартового произведения", "кортеж". На уровне реляционной модели используем термины "домен", "отношение", "кортеж". На уровне стандарта SQL и конкретных реализаций используем термины "тип данных", "таблица", "строка таблицы". И каждый раз речь идет об одном и том же.Учебное пособие имеет следующую структуру.
Первая глава содержит небольшое введение в математическую теорию множеств, необходимое для введения фундаментального понятия "отношение".
Следующие три главы содержат описание собственно реляционной модели данных. Во второй главе вводятся базовые понятия реляционной модели данных, такие как "домен", "отношение", "атрибут", "кортеж", "ключ", "внешний ключ". В третьей главе вводится понятие целостности реляционных данных. Даются понятия целостности сущностей и целостности внешних ключей. В четвертой главе описывается язык доступа к реляционным данным - реляционная алгебра.
Пятая глава содержит краткое описание и примеры применения стандартного языка доступа к реляционным данным - языка SQL.
Шестая и седьмая главы посвящены важным вопросам правильного проектирования отношений. В этих главах вводятся нормальные формы отношений. Понятие нормальных форм необходимо для проектирования непротиворечивых и неизбыточных таблиц базы данных.
В восьмой главе описывается альтернативный способ разработки таблиц в нормальной форме - модель "сущность-связь".
Последние три главы посвящены важному для баз данных понятию "транзакция". Понятие транзакции является фундаментальным при рассмотрении таких вопросов как поддержание целостности базы данных, независимой одновременной работы большого количества пользователей, восстановления данных после сбоев системы.
Таблица 1
|
Кого Кто |
Вовочка
Петя
Маша
Лена
|||
| Любит | |||
| Любит | |||
| Любит | Любит | ||
| Любит |
Таблица 1. Матрица взаимоотношенийСпособ 4. При помощи таблицы фактов:
 PNAME - наименование поставщика зависит от номера поставщика.
PNAME
PNAME - наименование поставщика зависит от номера поставщика.
PNAME  PNUM - номер поставщика зависит от наименования поставщика.
{PNUM, DNUM}
PNUM - номер поставщика зависит от наименования поставщика.
{PNUM, DNUM}  VOLUME - поставляемое количество зависит от первого ключа отношения.
{PNUM, DNUM}
VOLUME - поставляемое количество зависит от первого ключа отношения.
{PNUM, DNUM}  PNAME - наименование поставщика зависит от первого ключа отношения.
{PNAME, DNUM}
PNAME - наименование поставщика зависит от первого ключа отношения.
{PNAME, DNUM}  VOLUME - поставляемое количество зависит от второго ключа отношения.
{PNAME, DNUM}
VOLUME - поставляемое количество зависит от второго ключа отношения.
{PNAME, DNUM}  PNUM - номер поставщика зависит от второго ключа отношения.
Данное отношение не содержит неключевых атрибутов, зависящих от части сложного ключа (см. определение 2НФ). Действительно, от части сложного ключа зависят атрибуты PNAME и PNUM, но они сами являются ключевыми. Таким образом, отношение находится в 2НФ.
Кроме того, отношение не содержит зависимых друг от друга неключевых атрибутов, т.к. неключевой атрибут всего один - VOLUME (см. определение 3НФ). Таким образом, показано, что отношение "Поставки" находится в 3НФ.
Таким образом, описанный ранее алгоритм нормализации неприменим к данному отношению. Очевидно, однако, что аномалия данного отношения устраняется путем декомпозиции его на два следующих отношения:
PNUM - номер поставщика зависит от второго ключа отношения.
Данное отношение не содержит неключевых атрибутов, зависящих от части сложного ключа (см. определение 2НФ). Действительно, от части сложного ключа зависят атрибуты PNAME и PNUM, но они сами являются ключевыми. Таким образом, отношение находится в 2НФ.
Кроме того, отношение не содержит зависимых друг от друга неключевых атрибутов, т.к. неключевой атрибут всего один - VOLUME (см. определение 3НФ). Таким образом, показано, что отношение "Поставки" находится в 3НФ.
Таким образом, описанный ранее алгоритм нормализации неприменим к данному отношению. Очевидно, однако, что аномалия данного отношения устраняется путем декомпозиции его на два следующих отношения: